PDF・スキャン・ページのスクリーンショットをアップロード
まずは最も鮮明なサンプルを用意してください。PDFファイルをそのままアップロードしても、PDFページのスクリーンショットをドラッグしても、スキャン画像を使っても構いません。このPDF書体識別ツールは、見出し、タイトル、フォームラベル、本文サンプルが十分な大きさで写っていて、ストロークのコントラスト、字間、セリフ形状、文字の比率が確認できるほど精度が上がります。
PDFファイル、PDFページのスクリーンショット、またはスキャン画像をアップロードすると、見えているフォントを数秒で識別できます。このPDF書体識別ツールは、パンフレットのページ、帳票、表紙、PDF書き出しされたスライド、印刷用レイアウト、そして文字は見えていても元データを簡単には確認できないスキャン資料のような、実際の検索意図に合わせて設計されています。すぐに実用的な答えが欲しいとき、このページならフォント候補を特定し、結果の確からしさを把握し、近い代替フォントまで比較できます。
PDFファイルをドロップ、スクリーンショットを貼り付け、またはPDFページ画像を選択
パンフレットの表紙、印刷用フォーム、PDFレポート、スキャンしたチラシ、提案書、レイアウト書き出しなど、元データよりも見えている文字が重要な場面で同じ流れを使えます。
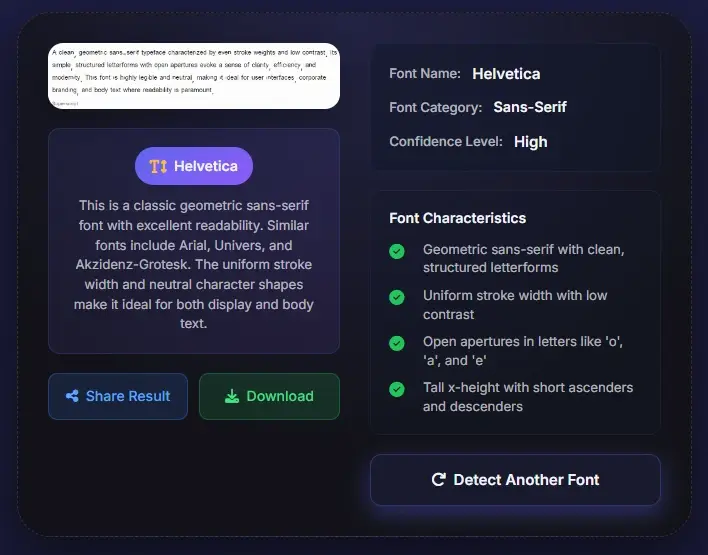

まずは最も鮮明なサンプルを用意してください。PDFファイルをそのままアップロードしても、PDFページのスクリーンショットをドラッグしても、スキャン画像を使っても構いません。このPDF書体識別ツールは、見出し、タイトル、フォームラベル、本文サンプルが十分な大きさで写っていて、ストロークのコントラスト、字間、セリフ形状、文字の比率が確認できるほど精度が上がります。
このワークフローは、PDFの内部情報ではなく、ページ上で実際に見えているフォントを対象にします。というのも、PDFから書体を調べたい人の多くは、フラット化されたレイアウト、スキャン文書、PDF書き出しされたスライド、あるいはファイル内のフォント一覧では答えにならないビジュアルサンプルを扱っているからです。
有力なフォント名、フォントカテゴリ、見た目の一致度、そして試す価値のある類似フォントを確認できます。元の書体がカスタム、サブセット化されたもの、商用フォント、あるいはPDF工程で改変されたものでも、この検出ツールなら近い代替候補と実用的な補足情報を返し、次の作業に進みやすくなります。
このキーワードの検索意図が強いケースは、PDF内のタイポグラフィは見えているのに、素早く確実に識別する手段がない状況です。このページは、そうした代表的なケースに合わせて作られています。
PDF書体識別ツールを探す人の多くは、営業資料、提案書、パンフレット、ホワイトペーパー、印刷用PDFを見ながら、今このページに使われているフォントを知りたいと考えています。その時点では、すべての埋め込みリソースを技術的に一覧化することが最優先とは限りません。必要なのは、目の前の見出し、本文、フォームラベルに対する速い答えです。このページは、まずその視覚的な答えを返し、必要ならその後でPDFプロパティの詳細確認へ進めるように設計されています。
スキャンPDFでは事情が変わります。人間には文字に見えていても、技術的には画像として扱われることが多く、検索可能にするには文字認識が必要になる場合があります。しかも、直接参照できるフォントメタデータが存在しないことも珍しくありません。契約書のスキャン、アーカイブ化されたチラシ、撮影した配布資料、古い文書画像を扱うなら、可視ページ画像から始めるPDF書体識別ツールの方が現実的です。
PDFには通常の本文以外の要素も多く含まれます。表紙、ポスター、パンフレット、商品資料、プレゼン書き出し、マーケティング用PDFでは、文字がグラフィック、バナー、図表、デザインブロックに焼き込まれていることがあります。そうした場合、PDFから書体を探す手段には、内部の技術情報だけでなく、見えている文字を視覚的に判定できる力が必要です。書体がページのアートワークにフラット化されているなら、このスクリーンショット起点の方法の方が、一般的なドキュメントプロパティ確認よりもユーザー意図に合っています。
デザイナーやマーケター、印刷担当者にとって、常に完全一致が必要とは限りません。多くの場合、必要なのは同じ印象を再現できる実用的な代替書体です。だからこそ、優れたPDF書体識別ツールは単一の候補だけでなく、類似フォントも返すべきです。ブランドレイアウトの再現、社内テンプレートの更新、提案資料づくり、保存したPDFのスタイル再現などでは、厳密な断定よりも、実務に使える近い候補の方が価値を持つことがあります。
PDF書体識別ツールを探している人は、実際には性質の異なる3つの方法を混同していることが多いです。最適な手段は、PDFがデジタルなのか、スキャンなのか、視覚的にフラット化されているのかで変わります。
このPDF書体識別ツールは、PDFページ、スキャン、スクリーンショット、表紙、フォーム、グラフィックの多いレイアウトに見えている文字を対象にしています。すべてのPDF内部フォントリソースを完璧に読み取ると約束するのではなく、実際に目で見えているタイポグラフィを識別することに集中しています。そのため、素早いフォント特定、見た目ベースの照合、実務で使える再現に向いています。
最適な用途: PDFページ、スキャン、パンフレット、フォーム、表紙に見えているタイポグラフィ
PDFの文書プロパティ確認は、デジタルPDF内で宣言されているフォントを確認したい場合に有力な選択肢です。フォントが埋め込みかサブセットかを確認でき、印刷データのトラブルシュートや文書リソースの検証に向いています。ただし、文字がアートワークにフラット化されていたり、手元にページのスクリーンショットしかない場合には、この流れだけでは不十分です。
最適な用途: ドキュメントプロパティ確認、埋め込みフォント検証、印刷前チェック
文字認識は、PDFが選択可能なテキストではなく、文字の画像として存在している場合に役立ちます。スキャン文書を検索可能に変換できますが、文字認識だけで正確なフォント識別まで保証できるわけではありません。実務では、文字認識でテキスト化しつつ、ユーザーが本当に知りたい書体の見た目の照合はPDF書体識別ツールに任せる方が合理的です。
最適な用途: スキャン資料、撮影文書、画像ベースのPDF
PDFには選択できるテキスト、埋め込みサブセット、画像化されたデザイン、スキャン画像が混在します。何をアップロードするかを整理します。
パンフレット、資料、メニュー、フォーム、プレゼン、スキャンでは、実際に見えている文字が対象です。見出しや本文の一部だけを切り出すと比較しやすくなります。
画像からフォントを検出デジタルPDFでテキストを選択できる場合、埋め込みフォント一覧は参考になります。ただしサブセット名や置換フォントが表示されることもあります。
Adobeでの確認と比較PDF制作ではアウトライン化、サブセット化、圧縮、わずかな変形が起こります。結果は実用的な見た目の候補として確認してください。
似ているフォントを比較このキーワードが難しい理由のひとつは、ユーザーがPDF書体識別ツールに期待していることが一様ではないからです。デジタルPDFの内部フォントを知りたい人もいれば、ページ全体が画像化されたスキャンPDFを扱っている人もいます。また、PDFビューアの画面を保存したスクリーンショットから、見えている書体だけを知りたい人もいます。このページは、そうした現実的な検索意図に合わせて作られています。ページ上に見えているフォントを識別しつつ、そのPDFが選択可能テキストなのか、スキャンなのか、フラット化されているのか、あるいはアートワークに埋め込まれているのかによって振る舞いが変わる理由まで説明します。単なる一般論ではなく、ユーザーが結果を信頼する前に必要な判断材料を提供する構成です。
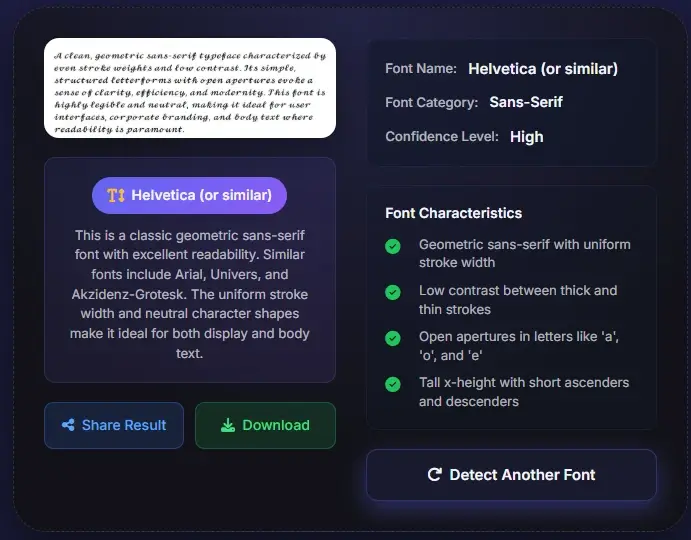
PDFのワークフローでは、通常の文書編集画面では見えない複雑さが生まれます。PDF内のフォントは、完全埋め込み、サブセット埋め込み、名前参照のみ、ビューア側での代替表示、あるいはグラフィックとしてフラット化された状態かもしれません。だからこそ、PDF確認ツール上のフォント名が見慣れない形式になったり、見えている文字と単純なフォント一覧が一致しなかったりします。このPDF書体識別ツールは、その問題をユーザー意図の側から処理します。ページ上で見えているタイポグラフィをそのまま識別対象にするので、一般的なファミリーに近ければすぐ先へ進めますし、カスタム、サブセット、強い加工が疑われる場合でも、PDF用語だけで行き詰まらず、実用的な代替候補へつなげられます。

価値のあるPDF書体識別ページは、抽象的な説明で終わりません。具体的な作業に役立つ必要があります。このページは、PDF提案書のタイトルを再現したい、パンフレット見出しの書体を知りたい、商品資料のタイポグラフィを確認したい、帳票のスタイルを再構築したい、PDF化したスライドデッキに近い代替書体を探したい、といった高意図のケースに合わせて設計されています。こうした場面では、ファイル内部の技術情報よりも、目に見えるフォントサンプルの方が重要です。そのため、このページはスクリーンショットベース・ページベースの認識を重視しており、デザイン流用、内容更新、テンプレート再構築、競合調査を素早く進める用途に向いています。
PDFプロパティ確認、プリフライト、文字認識といった手法にも、それぞれ重要な役割があります。印刷前に埋め込みリソースを確認しなければならない場合、それらは非常に有効です。ただし、PDFから書体を調べたい多くの人が欲しいのは、もっと速く、もっと負担の少ない最初の一歩です。PDFページを見て、有力なフォントを知り、近い代替候補を比較し、そのまま作業を進めたいのです。このページは、まさにその低摩擦なワークフローのためにあります。ファイルやスクリーンショットをアップロードし、結果を確認し、サンプルがスキャンっぽいのか、フラット化されていそうかを把握したうえで、必要なら技術的な深掘りに進めば十分です。その意味で、このツールは非技術者にも、重いデスクトップソフトを開く前にタイポグラフィの答えだけ先に欲しい実務チームにも使いやすい入口になります。

方法は大きく2つあります。デジタルPDFの文書レベルのフォント一覧が知りたいなら、PDF閲覧ソフトの文書プロパティでファイル内に宣言されているフォントを確認できます。一方、スクリーンショット、スキャン、表紙、フラット化されたアートワークなど、ページ上に見えている文字を識別したいなら、このページのようなPDF書体識別ツールの方が速くて実用的です。PDFまたはページ画像をアップロードすると、可視の文字形からフォントを解析できます。
はい。むしろ、それがこのページの重要な用途のひとつです。スキャンPDFは通常のテキスト文書というより画像に近く、直接確認できるフォントメタデータを持たないことがあります。その場合、元ファイルから情報を抜こうとするより、ページ上に見えている文字形を視覚的に識別する方が現実的です。
埋め込みサブセットとは、その文書で実際に使われている文字だけを含むフォントデータがPDF内に埋め込まれている状態を指します。ファイルサイズを小さくできますが、PDF検査ツール上ではフォント名が見慣れない表示になることがあります。意味の分かりにくい接頭辞が付いたファミリー名が見えても、それは別のフォントではなく、サブセット化された同系統の書体である可能性が高いです。
PDFツールでは、サブセット接頭辞、内部リソース名、代替表示されたフォント名などが表示されることがあり、普段目にするフォント名と一致しない場合があります。さらに、PDFが要求しているフォントと、実際にビューアが表示している文字が、代替フォントの影響で完全には一致しないこともあります。そのため、ファイル内部情報が分かりにくい場合でも、可視テキストを基準に判断するPDF書体識別ツールは有効です。
このページでは両方に対応しています。手元にファイルがあるならPDFを直接アップロードできますし、PDFビューアで保存したページ画像やスクリーンショットを使っても構いません。どちらの場合も目的は、PDF内部の全リソース一覧を約束することではなく、ページ上に実際に見えているフォントを識別することです。
それはPDFの実務ではよくあることです。表紙、パンフレット、販促レイアウトでは、独自ブランドフォント、有料書体、あるいはページデザインに焼き込まれた文字が使われている場合があります。そのようなとき、最も実用的な答えは完全一致ではなく、近い見た目の候補と類似フォントの提示になることがあります。それでも、見た目の再現、レイアウト更新、互換フォント選定には十分役立ちます。
はい。プロパティ確認はPDFに埋め込まれた情報を見ます。画像ベースのPDFフォント検索はページ上に見えている字形を分析します。