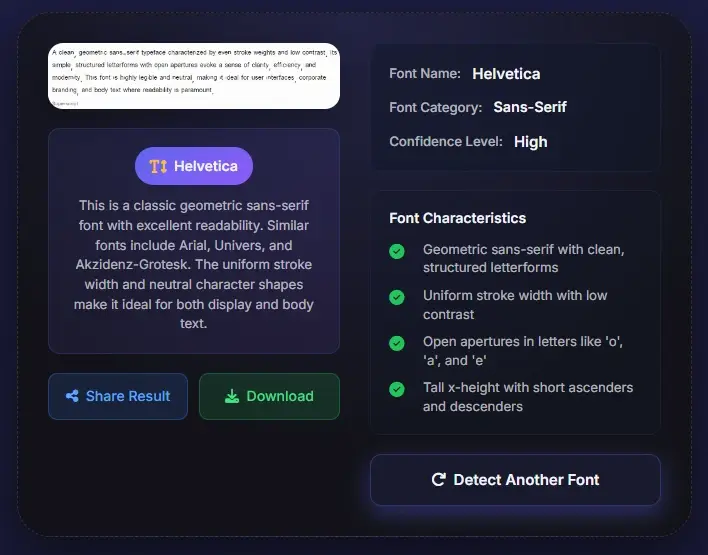
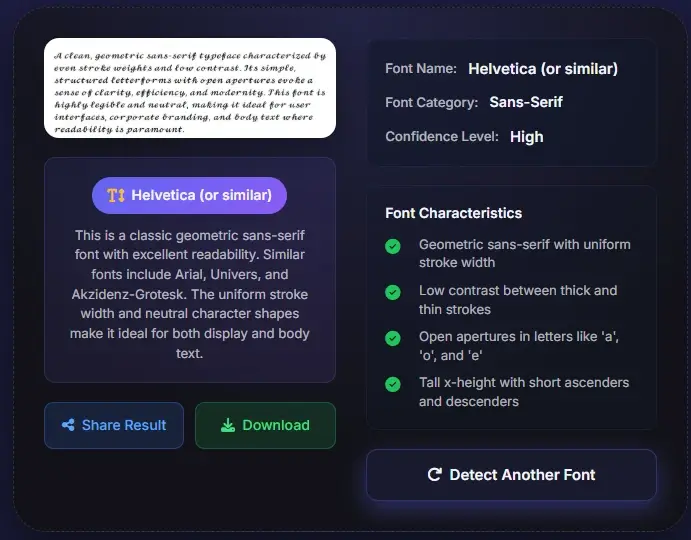
Ein praktischer Einstieg vor tieferer PDF-Prüfung
Natürlich haben Acrobat, Preflight-Prüfungen und OCR-Abläufe weiterhin ihren Platz. Wenn du eingebettete Ressourcen für die Druckproduktion bestätigen musst, sind diese Werkzeuge wertvoll. Aber viele Menschen, die eine Schrift aus PDF erkennen möchten, wollen zuerst einen schnelleren und unkomplizierteren Einstieg. Sie wollen eine PDF-Seite sehen, die wahrscheinliche Schrift erkennen, nahe Alternativen vergleichen und weiterarbeiten. Genau dafür ist diese Seite da. Lade die Datei oder den Screenshot hoch, prüfe den Treffer, notiere dir, ob die Probe gescannt oder abgeflacht wirkt, und entscheide dann, ob du tiefer technisch prüfen musst. In der Praxis macht das das Tool sowohl für nicht-technische Nutzer als auch für erfahrene Teams nützlich, die vor einem schwereren lokalen Prüfablauf erst einmal schnell eine typografische Antwort brauchen.